




.png)
Validator Uptime in Staking
In 2025, uptime is no longer about simply staying online. It is about operating infrastructure that can withstand real-world stress, adapt to evolving networks, and remain reliable as meaningful economic activity moves on-chain.
This guide explores what validator uptime truly means today, why it matters more than ever, and how professional operators like Node.Monster approach reliability as a core responsibility.
What Validator Uptime Really Means
Validator uptime is often described as the percentage of time a node is online, but this definition is overly simplistic.
In practice, a validator is only considered “up” when it can actively participate in consensus. That means proposing blocks when selected, attesting to others' proposed blocks, staying fully synchronized with the network, and responding correctly to protocol events.
A validator can be technically running while still underperforming. If it is lagging behind the chain, suffering from latency, or misconfigured, it is effectively offline from the protocol’s perspective. Because Proof-of-Stake relies on continuous participation, even brief interruptions can have tangible consequences.
Why Validator Uptime Matters in Modern Staking
Uptime touches every layer of the staking experience.
For delegators, uptime directly affects rewards. Validators that consistently participate in consensus capture more of the available rewards, whereas downtime results in missed attestations or proposals and, over time, reduced effective yield.
For networks, uptime is a security concern. A resilient validator set ensures reliable finality and helps maintain stability during periods of congestion or stress. When many validators experience downtime, the network becomes more fragile and less predictable.
There is also a risk component. Many PoS networks impose penalties for missed participation or misbehavior. While severe slashing events are uncommon among well-run validators, they are almost always tied to operational failures. From a delegator’s perspective, uptime is therefore closely linked to risk management.
Finally, uptime has become a trust signal. As staking grows more competitive and transparent, delegators increasingly look at historical performance and operational reputation when selecting validators.
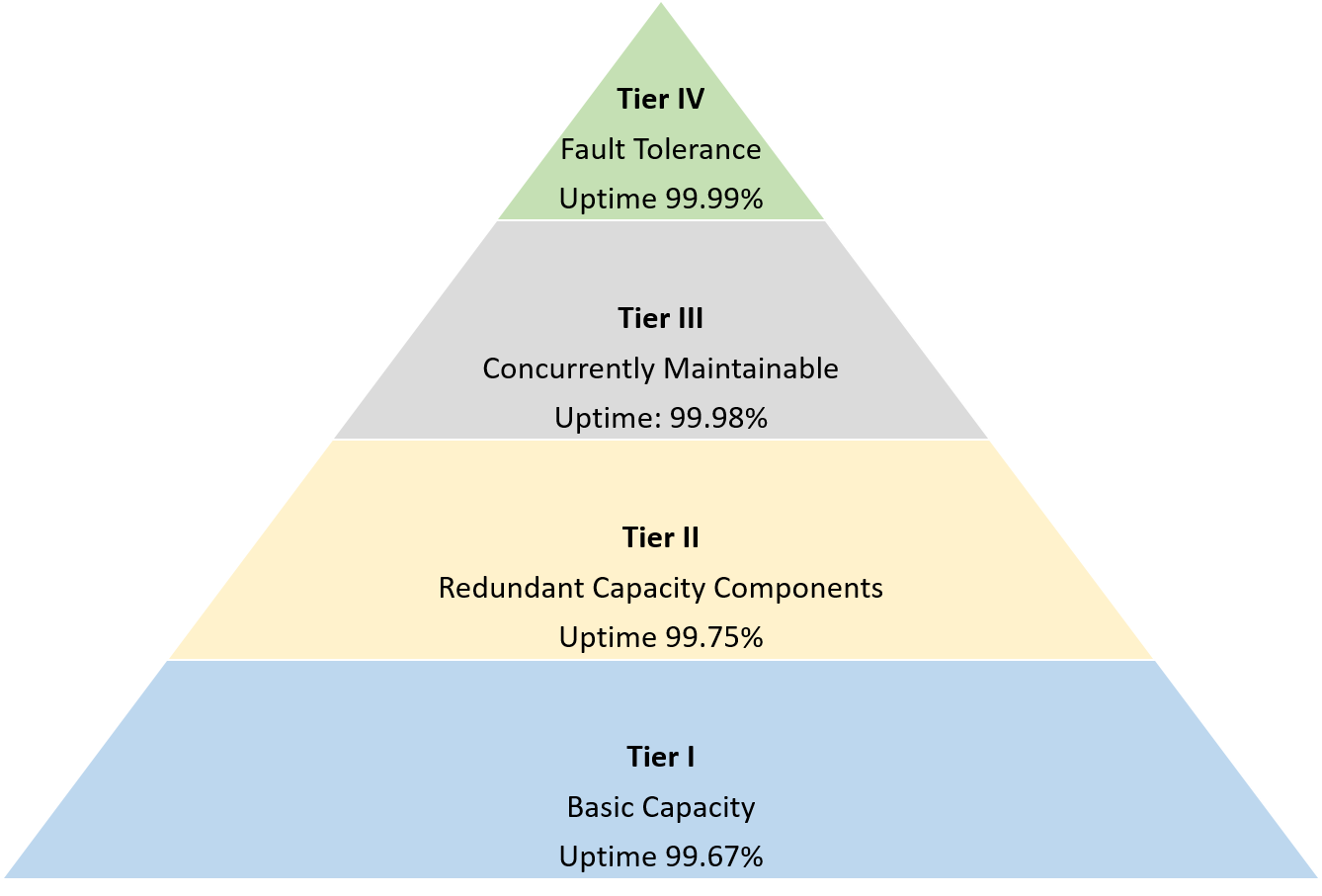
How Uptime Is Measured and Interpreted
Uptime is typically expressed as a percentage calculated using the formula:
(Total Time – Downtime) / Total Time × 100
Different protocols define participation differently. Some focus on missed attestations; others track proposal success or broader validator behavior. Public dashboards can provide surface-level indicators, but professional operators rely on deeper internal monitoring to understand whether validators are effectively contributing to consensus.
Actual uptime is not just about server availability. It is about consistent, protocol-level participation.
The Real Cost of Downtime
Downtime rarely causes immediate failure, but its effects accumulate.
Missed participation reduces staking efficiency and lowers rewards over time. For larger delegations, even small performance gaps can become significant over the long term.
Operational instability also increases exposure to penalties. Networks are designed to discourage unreliable behavior, and validators who consistently fail to meet participation requirements may face reduced rewards or other consequences.
Beyond the numbers, downtime damages credibility. As performance metrics become more visible, validators with unreliable track records often lose delegators.
How Node.Monster Approaches Validator Uptime (Monitoring, Observability, and SLA)
High uptime is only achievable with continuous visibility into system health. At Node.Monster, monitoring and observability are foundational components of validator operations.
Validator infrastructure is monitored around the clock using real-time analytics, automated alerting, and manual oversight. Performance metrics are tracked using industry-standard tooling such as Grafana and Prometheus, allowing early detection of resource constraints, synchronization issues, or abnormal behavior before they impact consensus participation.
Security monitoring is tightly integrated into this process. Immediate alerts are triggered for suspicious activity or potential threats, enabling rapid response and reducing the likelihood that security incidents translate into downtime.
For critical infrastructure, Node.Monster operates under service-level commitments that include uptime of 99.9% availability, supported by multi-region and multi-cloud redundancy. These guarantees reflect the operational standards required by professional and institutional stakeholders.
By combining observability, automation, and human oversight, uptime becomes a managed outcome rather than a reactive metric.
The Future of Validator Uptime in Staking
As staking infrastructure continues to mature, validator uptime is increasingly viewed through an institutional lens. More funds, enterprises, and regulated entities are exploring staking not as an experimental activity, but as a long-term yield and infrastructure strategy.
With that shift comes a different set of expectations. Institutional participants evaluate validators using criteria that go far beyond simple reward rates or brand recognition.
These expectations typically include:
- Clear operational standards around reliability and performance
- Strong security practices aligned with institutional risk management
- Transparent reporting and observability into validator behavior
- Infrastructure that can scale alongside growing delegations
The ability to meet these requirements consistently is what separates professional validation services from smaller or opportunistic operators.
At Node.Monster, validator uptime is approached as part of a broader operational framework. Reliability is not treated as a single metric, but as the outcome of infrastructure design, monitoring, security practices, and disciplined operations. This approach allows us to support networks and delegators that require predictable, long-term performance.
The growing institutional interest in staking reflects a broader maturation of the Proof-of-Stake ecosystem. As more value flows into these networks, uptime and operational reliability move from competitive advantages to baseline expectations.
Looking ahead, several trends are becoming increasingly clear:
- Delegators are placing greater emphasis on proven operational history.
- Performance transparency is becoming more visible through dashboards and monitoring tools.
- Institutional staking will favor validators that can integrate cleanly into professional workflows while maintaining consistent participation.
In this environment, uptime is no longer about marketing claims. It is about demonstrating reliability over time, across market conditions, and through network upgrades.
If you are evaluating validator infrastructure for long-term staking, Node.Monster is always open to discussing how professional operations and resilient infrastructure can support your strategy.
Conclusion
Validator uptime is central to staking performance, network security, and delegator trust. It influences rewards, reduces operational risk, and strengthens the overall ecosystem.
It's no longer about avoiding downtime. It is about building infrastructure and operational practices that can support networks as they scale and as staking becomes a foundational part of global financial systems.
At Node.Monster, uptime is approached as a long-term commitment to the networks we support. By focusing on resilience, monitoring, and disciplined operations, we aim to contribute to healthier Proof-of-Stake ecosystems and more dependable outcomes for delegators.